from fastMONAI.vision_all import *
from monai.apps import DecathlonDataset
from sklearn.model_selection import train_test_split
import torchio as tioPatch-Based Binary Segmentation
Patch-based training for 3D medical image segmentation using fastMONAI’s
MedPatchDataLoaders with lazy loading, where volumes are loaded on-demand, keeping memory usage constant regardless of dataset size.
![]()
Download external data
We use the MONAI function DecathlonDataset to download the Heart MRI dataset from the Medical Segmentation Decathlon challenge.
path = Path('../data')
path.mkdir(exist_ok=True)task = "Task02_Heart"
training_data = DecathlonDataset(root_dir=path, task=task, section="training",
download=True, cache_num=0, num_workers=3)2026-07-01 11:18:34,043 - INFO - Verified 'Task02_Heart.tar', md5: 06ee59366e1e5124267b774dbd654057.
2026-07-01 11:18:34,044 - INFO - File exists: ../data/Task02_Heart.tar, skipped downloading.
2026-07-01 11:18:34,045 - INFO - Non-empty folder exists in ../data/Task02_Heart, skipped extracting.df = pd.DataFrame(training_data.data)
df.shape(16, 2)Split the labeled data into training and test sets.
train_df, test_df = train_test_split(df, test_size=0.1, random_state=42)
train_df.shape, test_df.shape((14, 2), (2, 2))Analyze training data
Use MedDataset to analyze the dataset and get preprocessing recommendations.
med_dataset = MedDataset(img_list=train_df.label.tolist(), dtype=MedMask, max_workers=12)MedDataset cache: 14 cached, 0 processedmed_dataset.df.head()| path | content_hash | dim_0 | dim_1 | dim_2 | voxel_0 | voxel_1 | voxel_2 | orientation | label_1_volume_mm3 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | ../data/Task02_Heart/labelsTr/la_023.nii.gz | a4b0e976cf03b0f1ffdbf79ae91281c4 | 320 | 320 | 110 | 1.25 | 1.25 | 1.37 | RAS+ | 92483.5628 |
| 1 | ../data/Task02_Heart/labelsTr/la_004.nii.gz | db5dcb7cce258526726054f56bf015ef | 320 | 320 | 110 | 1.25 | 1.25 | 1.37 | RAS+ | 125173.0473 |
| 2 | ../data/Task02_Heart/labelsTr/la_007.nii.gz | 4b1c1bf9d0d1adfb12d287c7aa200edc | 320 | 320 | 130 | 1.25 | 1.25 | 1.37 | RAS+ | 118684.8129 |
| 3 | ../data/Task02_Heart/labelsTr/la_022.nii.gz | f9c20e542980932d2ea19a56f3bc7a60 | 320 | 320 | 110 | 1.25 | 1.25 | 1.37 | RAS+ | 71820.1096 |
| 4 | ../data/Task02_Heart/labelsTr/la_011.nii.gz | f1dd0a596e4daf898c3287441971cc06 | 320 | 320 | 120 | 1.25 | 1.25 | 1.37 | RAS+ | 125130.2348 |
data_info_df = med_dataset.summary()suggestion = med_dataset.get_suggestion()
target_spacing = suggestion['target_spacing']
target_spacing[1.25, 1.25, 1.37]stats = med_dataset.get_size_statistics(target_spacing=target_spacing)
print(f"Image sizes (after resampling to {target_spacing}):")
print(f" Min: {stats['min']}")
print(f" Median: {stats['median']}")
print(f" Max: {stats['max']}")
suggested_size = suggest_patch_size(med_dataset, target_spacing=target_spacing)
print(f"\nSuggested patch size: {suggested_size}")Image sizes (after resampling to [1.25, 1.25, 1.37]):
Min: [320.0, 320.0, 90.0]
Median: [320.0, 320.0, 110.0]
Max: [320.0, 320.0, 130.0]
Suggested patch size: [256, 256, 80]Dim 2: patch_size reduced from 96 to 80 to fit smallest volume (min=90, median=110).Configure patch-based training
PatchConfig centralizes all patch-related parameters:
- patch_size: Size of extracted patches
[x, y, z], should be divisible by 16 for UNet compatibility - samples_per_volume: Number of patches extracted per volume per epoch
- sampler_type:
'uniform'(random) or'label'(foreground-weighted) - label_probabilities: For
'label'sampler, probability of sampling each class - queue_length: Number of patches to keep in memory buffer
- patch_overlap: Overlap for inference (float 0-1 for fraction, or int for pixels)
- aggregation_mode: How to combine overlapping patches (
'hann'for smooth boundaries) - padding_mode: Padding mode when image < patch_size (0 = zero padding, nnU-Net standard)
patch_config = PatchConfig(
patch_size=[160, 160, 80],
samples_per_volume=8,
sampler_type='label',
label_probabilities={0: 0.5, 1: 0.5},
patch_overlap=0.5,
keep_largest_component=True,
target_spacing=target_spacing,
aggregation_mode='hann',
# normalization is set once on the config and applied at both training and inference
# (no need to re-specify it at inference time).
normalization=[ZNormalization(masking_method='foreground')]
)
print(f"Patch config: {patch_config}")Patch config: PatchConfig(patch_size=[160, 160, 80], patch_overlap=0.5, samples_per_volume=8, sampler_type='label', label_probabilities={0: 0.5, 1: 0.5}, queue_length=300, queue_num_workers=4, aggregation_mode='hann', apply_reorder=True, target_spacing=[1.25, 1.25, 1.37], preprocessed=False, padding_mode=0, keep_largest_component=True, binary_threshold=0.5, normalization=[{'name': 'ZNormalization', 'masking_method': 'foreground', 'channel_wise': True}])Alternatively, use PatchConfig.from_dataset(med_dataset) to auto-configure the patch size from the dataset analysis.
Define transforms
Normalization is set on the PatchConfig above (normalization=...) and applied at both training and inference, so training and inference use the same preprocessing.
The remaining stage is patch_tfms: augmentations applied to extracted patches during training only.
suggest_patch_size returns a size that fits every volume, so no padding is needed at training time. Here we pick [160, 160, 80] manually; it is also smaller than every volume, so it needs no padding either.
You can still pass pre_patch_tfms= to from_df (or pre_inference_tfms= at inference) to override the config, which is useful for transforms that are not serializable.
patch_tfms = [
RandomAffine(scales=(0.7, 1.4), degrees=30, translation=(25, 25, 10), p=0.2),
RandomAnisotropy(downsampling=(1.5, 3), p=0.25),
RandomGamma(log_gamma=(-0.3, 0.3), p=0.3),
RandomIntensityScale(scale_range=(0.75, 1.25), p=0.1),
RandomNoise(std=0.1, p=0.1),
RandomBlur(std=(0.5, 1.0), p=0.2),
RandomFlip(axes='LRAPIS', p=0.5),
]Alternative: GPU-batched augmentation
For long training runs (e.g., hundreds of epochs), GPU-batched augmentation can reduce training time by moving transforms from CPU to GPU. Instead of per-sample TorchIO transforms (patch_tfms), gpu_patch_augmentations creates a batched augmentation pipeline that operates on GPU tensors directly.
Because it is genuinely batched (one grid_sample over the whole batch), it is far faster than per-sample augmentation. Measured on an RTX 6000 Ada (full pipeline, 128^3): ~3 ms/batch vs ~77 ms for the equivalent MONAI per-sample-on-GPU pipeline (~25x) and ~287 ms for the TorchIO CPU path (~100x).
It is an approximate reimplementation of the patch_tfms transforms (voxel-space affine, per-axis flip, image-only anisotropy, sign-preserving gamma), It approximates the CPU path rather than matching it exactly. Use gpu_augmentation instead of patch_tfms (they are mutually exclusive).
# # GPU augmentation alternative (uncomment to use instead of patch_tfms above)
# gpu_aug = gpu_patch_augmentations(patch_config.patch_size, patch_config.target_spacing)
#
# # Then pass gpu_augmentation instead of patch_tfms to from_df:
# # dls = MedPatchDataLoaders.from_df(
# # ..., gpu_augmentation=gpu_aug, ... # replaces patch_tfms=patch_tfms
# # )Create patch-based DataLoaders
MedPatchDataLoaders uses lazy loading: - Only file paths are stored at creation time (~0 MB) - Volumes are loaded on-demand by Queue workers
bs = 4
dls = MedPatchDataLoaders.from_df(
df=train_df,
img_col='image',
mask_col='label',
valid_pct=0.1,
patch_config=patch_config,
patch_tfms=patch_tfms,
bs=bs,
seed=42
)
print(f"Training subjects: {len(dls.train.subjects_dataset)}")
print(f"Validation subjects: {len(dls.valid.subjects_dataset)}")Training subjects: 13
Validation subjects: 1batch = next(iter(dls.train))
x, y = batch
print(f"Batch shape - Image: {x.shape}, Mask: {y.shape}")Batch shape - Image: torch.Size([4, 1, 160, 160, 80]), Mask: torch.Size([4, 1, 160, 160, 80])dls.show_batch(anatomical_plane=2, max_n=2, overlay=False)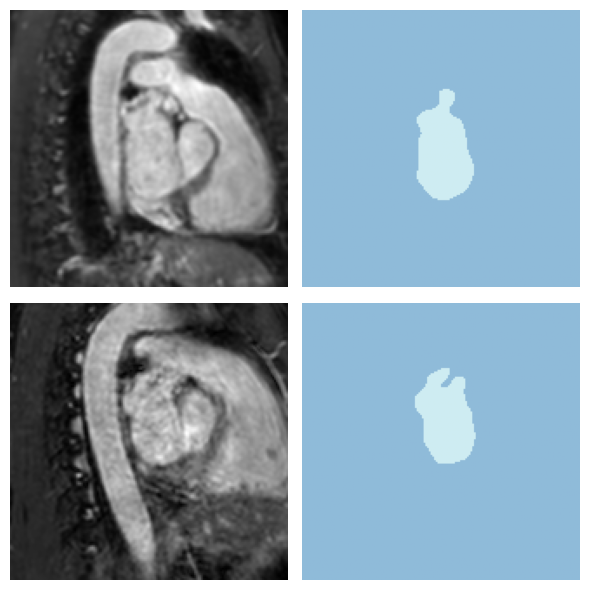
Create and train a 3D model
We use MONAI’s UNet with: - out_channels=2: Softmax output (background + foreground) - Instance normalization: Common in medical imaging - DiceCELoss: Combines Dice loss with Cross-Entropy for stable training
from monai.networks.nets import UNet
from monai.networks.layers import Norm
from monai.losses import DiceCELoss- DiceCELoss: Combines Dice loss with Cross-Entropy for stable training.
batch=Truecomputes Dice by pooling TP/FP/FN across all samples in the batch before computing the ratio (nnU-Net default), rather than averaging per-sample Dice scores. This provides more stable gradients when some patches contain little or no foreground.
model = UNet(
spatial_dims=3,
in_channels=1,
out_channels=2,
channels=(16, 32, 64, 128, 256),
strides=(2, 2, 2, 2),
num_res_units=2,
norm=Norm.INSTANCE
)
loss_func = CustomLoss(loss_func=DiceCELoss(
to_onehot_y=True,
softmax=True,
include_background=False,
batch=True
))We use AccumulatedDice metric which accumulates true positives, false positives, and false negatives across all validation batches before computing Dice.
learn = Learner(dls, model, loss_func=loss_func, metrics=[AccumulatedDice(n_classes=2)])learn.lr_find()SuggestedLRs(valley=0.0014454397605732083)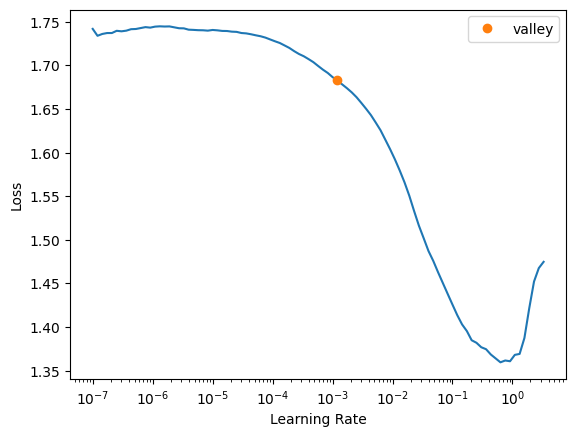
lr = 1e-3best_model_fname = "best_heart_patch"
save_best = EMACheckpoint(
monitor='accumulated_dice',
momentum=0.9,
comp=np.greater,
fname=best_model_fname,
with_opt=False
)# All params (size, transforms, loss, model name, etc.) are extracted from learn automatically
mlflow_callback = create_mlflow_callback(learn, experiment_name="Task02_Heart_Patch", dataset_version=med_dataset.fingerprint)
learn.fit_one_cycle(40, lr, cbs=[mlflow_callback, save_best])Logged train/val split (14 rows) to MLflow artifacts| epoch | train_loss | valid_loss | accumulated_dice | time |
|---|---|---|---|---|
| 0 | 1.863338 | 1.833228 | 0.025057 | 00:10 |
| 1 | 1.798334 | 1.746731 | 0.036763 | 00:12 |
| 2 | 1.730990 | 1.646269 | 0.062455 | 00:12 |
| 3 | 1.665739 | 1.577626 | 0.068901 | 00:13 |
| 4 | 1.584245 | 1.457354 | 0.105605 | 00:12 |
| 5 | 1.471115 | 1.341621 | 0.149876 | 00:12 |
| 6 | 1.351944 | 1.154231 | 0.424962 | 00:12 |
| 7 | 1.223630 | 1.104443 | 0.248575 | 00:12 |
| 8 | 1.118729 | 0.981038 | 0.378676 | 00:12 |
| 9 | 0.998248 | 0.819083 | 0.583493 | 00:13 |
| 10 | 0.877727 | 0.877824 | 0.372700 | 00:13 |
| 11 | 0.770178 | 0.754741 | 0.453254 | 00:13 |
| 12 | 0.648433 | 0.483015 | 0.720920 | 00:12 |
| 13 | 0.538707 | 0.620015 | 0.525613 | 00:13 |
| 14 | 0.453362 | 0.620417 | 0.553635 | 00:12 |
| 15 | 0.413046 | 0.590110 | 0.528639 | 00:13 |
| 16 | 0.375575 | 0.429770 | 0.663679 | 00:13 |
| 17 | 0.336897 | 0.414838 | 0.664799 | 00:12 |
| 18 | 0.312887 | 0.451577 | 0.634654 | 00:12 |
| 19 | 0.288260 | 0.433174 | 0.647126 | 00:13 |
| 20 | 0.275838 | 0.379937 | 0.687469 | 00:12 |
| 21 | 0.259726 | 0.357459 | 0.705091 | 00:13 |
| 22 | 0.238610 | 0.448516 | 0.635598 | 00:12 |
| 23 | 0.240977 | 0.370313 | 0.693076 | 00:12 |
| 24 | 0.224594 | 0.396030 | 0.673184 | 00:12 |
| 25 | 0.209325 | 0.401551 | 0.668675 | 00:12 |
| 26 | 0.196984 | 0.486654 | 0.607467 | 00:12 |
| 27 | 0.191461 | 0.232734 | 0.807030 | 00:12 |
| 28 | 0.188933 | 0.337831 | 0.719086 | 00:12 |
| 29 | 0.184259 | 0.345416 | 0.713806 | 00:13 |
| 30 | 0.183472 | 0.386848 | 0.685132 | 00:12 |
| 31 | 0.173565 | 0.237175 | 0.799902 | 00:12 |
| 32 | 0.169383 | 0.319305 | 0.732026 | 00:13 |
| 33 | 0.166748 | 0.321408 | 0.723544 | 00:12 |
| 34 | 0.163314 | 0.356697 | 0.703021 | 00:12 |
| 35 | 0.157908 | 0.335025 | 0.718309 | 00:12 |
| 36 | 0.156667 | 0.297457 | 0.748900 | 00:12 |
| 37 | 0.160742 | 0.280017 | 0.762760 | 00:13 |
| 38 | 0.155448 | 0.293765 | 0.752271 | 00:12 |
| 39 | 0.145920 | 0.298501 | 0.751130 | 00:12 |
Training finished. Logging model artifacts to MLflow...
Logged best model weights: best_weights.pth
Logged final epoch learner: final_learner.pkl
Loaded best model weights (best_heart_patch) for best learner export
Logged best epoch learner: best_learner.pklSaved file doesn't contain an optimizer state.
2026/07/01 11:27:51 WARNING mlflow.pytorch: Saving pytorch model by Pickle or CloudPickle format requires exercising caution because these formats rely on Python's object serialization mechanism, which can execute arbitrary code during deserialization.The recommended safe alternative is to set 'export_model' to True to save the pytorch model using the safe graph model format.
2026/07/01 11:27:51 WARNING mlflow.utils.requirements_utils: Found torch version (2.6.0+cu124) contains a local version label (+cu124). MLflow logged a pip requirement for this package as 'torch==2.6.0' without the local version label to make it installable from PyPI. To specify pip requirements containing local version labels, please use `conda_env` or `pip_requirements`.MLflow run completed. Run ID: fb544eed3bd84cdd986bdfe049acee82Registered model 'UNet' already exists. Creating a new version of this model...
Created version '52' of model 'UNet'.learn.recorder.plot_loss();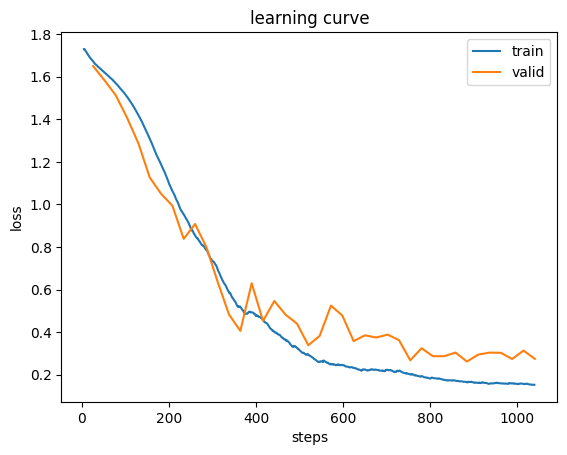
Save configuration for inference
The PatchConfig holds the key inference parameters (normalization, apply_reorder, target_spacing). Persist it with store_patch_variables (JSON); the inference notebook reloads it and reapplies normalization automatically. (padding_mode and binary_threshold are not saved and fall back to their defaults on reload.)
store_patch_variables(
config_fn='patch_config.json',
patch_size=patch_config.patch_size,
patch_overlap=patch_config.patch_overlap,
aggregation_mode=patch_config.aggregation_mode,
apply_reorder=patch_config.apply_reorder,
target_spacing=patch_config.target_spacing,
sampler_type=patch_config.sampler_type,
label_probabilities=patch_config.label_probabilities,
samples_per_volume=patch_config.samples_per_volume,
queue_length=patch_config.queue_length,
queue_num_workers=patch_config.queue_num_workers,
keep_largest_component=patch_config.keep_largest_component,
normalization=patch_config.normalization
)
print("Configuration saved to patch_config.json")Configuration saved to patch_config.jsonEvaluate on validation set
Evaluate the trained model on the validation set using sliding-window patch inference.
Metrics: - DSC: Dice score, overlap similarity (higher = better) - HD95: 95th percentile Hausdorff distance in mm (lower = better) - Sens: Sensitivity, the true-positive rate (higher = better) - LDR: Lesion detection rate (higher = better) - RVE: Relative volume error (0 = optimal, + = over-seg, - = under-seg)
val_subjects = dls.valid.subjects_dataset
val_img_paths = [str(s['image'].path) for s in val_subjects]
val_mask_paths = [str(s['mask'].path) for s in val_subjects]
print(f"Validation set: {len(val_img_paths)} images")Validation set: 1 imageslearn.load(best_model_fname)
print(f"Loaded best model: {best_model_fname}")
learn.export(f"models/best_learner.pkl")
save_dir = Path('predictions/patch_heart_val')
predictions = patch_inference(
learner=learn,
config=patch_config,
file_paths=val_img_paths,
save_dir=str(save_dir),
progress=True,
tta=True
)
print(f"\nSaved {len(predictions)} predictions to {save_dir}/")Loaded best model: best_heart_patchSaved file doesn't contain an optimizer state.
Saved 1 predictions to predictions/patch_heart_val/from fastMONAI.vision_metrics import (calculate_dsc, calculate_surface_metrics,
calculate_confusion_metrics,
calculate_lesion_detection_rate,
calculate_signed_rve)
results = []
for i, pred in enumerate(predictions):
img_name = Path(val_img_paths[i]).name
gt_path = val_mask_paths[i]
# Ground truth and prediction are both in native voxel space (patch_inference resizes the
# prediction back to the original grid), so load the GT natively too.
gt = MedMask.create(gt_path)
pred_5d = pred.unsqueeze(0).float()
gt_5d = gt.data.unsqueeze(0).float()
dsc = calculate_dsc(pred_5d, gt_5d).mean().item()
# Spacing-aware HD95 in mm: use the per-case voxel spacing read from the GT file.
# Predictions and GT live in native space, so the annotation's own resolution is correct.
hd95 = calculate_surface_metrics(pred_5d, gt_5d, spacing_mm=tio.LabelMap(gt_path).spacing)['hd95_mm']
sens = calculate_confusion_metrics(pred_5d, gt_5d, "sensitivity").nanmean().item()
ldr = calculate_lesion_detection_rate(pred_5d, gt_5d).nanmean().item()
rve = calculate_signed_rve(pred_5d, gt_5d).nanmean().item()
results.append({
'image': img_name, 'dsc': dsc, 'hd95': hd95,
'sensitivity': sens, 'ldr': ldr, 'rve': rve
})
results_df = pd.DataFrame(results)mlflow_callback.log_metrics_table(results_df, display=True)
mlflow_callback.log_metrics(
{f'val_{m}': results_df[m].mean() for m in results_df.select_dtypes(include='number').columns}
)
mlflow_callback.log_dataframe(results_df)
Logged metrics table to MLflow run fb544eed3bd84cdd986bdfe049acee82
Logged 5 metric(s) to MLflow run fb544eed3bd84cdd986bdfe049acee82
Logged DataFrame (1 rows) to MLflow run fb544eed3bd84cdd986bdfe049acee82from fastMONAI.vision_plot import show_segmentation_comparison
idx = 0
val_img = MedImage.create(
val_img_paths[idx],
apply_reorder=patch_config.apply_reorder,
target_spacing=patch_config.target_spacing
)
val_gt = MedMask.create(
val_mask_paths[idx],
apply_reorder=patch_config.apply_reorder,
target_spacing=patch_config.target_spacing
)
show_segmentation_comparison(
image=val_img,
ground_truth=val_gt,
prediction=predictions[idx],
metric_value=results_df.iloc[idx]['dsc'],
voxel_size=patch_config.target_spacing,
anatomical_plane=2 # axial view
)
View experiment tracking
mlflow_ui = MLflowUIManager()
mlflow_ui.start_ui()TrueSummary
In this tutorial, we demonstrated patch-based training and evaluation for 3D medical image segmentation:
Training: 1. PatchConfig: Centralized configuration for patch size, sampling, and inference parameters 2. MedPatchDataLoaders: Memory-efficient lazy loading with TorchIO Queue 3. Transforms: normalization on the config (applied to the full volume) plus patch_tfms (training augmentation) 4. AccumulatedDice: nnU-Net-style accumulated metric for patch-level validation 5. store_patch_variables(): Save configuration for inference consistency
Evaluation: 6. patch_inference(): Batch sliding-window inference with NIfTI output 7. Metrics: DSC, HD95, Sensitivity, LDR, RVE
Preprocessing parameters (normalization, apply_reorder, target_spacing) must match between training and inference for correct predictions.
mlflow_ui.stop()
MLflow UI was started externally — not stopping it